Have you ever seen a test suite actually prevent 100% of bugs? With all of the time that we spend testing software, how do bugs still get through? Testing seems ostensibly simple – there are only so many branches in the code, only so many buttons in the UI, only so many edge cases to consider. So what is difficult about testing software?
This post is dedicated to Edmund Clarke, who spent a large portion of his life pioneering solutions to the state explosion problem.
State Space and the Incomplete Guarantees of Branch Coverage
Consequently, drawing conclusions about software quality short of testing every possible input to the
program is fraught with danger.
When we think of edge cases, we intuitively think of branches in the code. Take the following trivial example:
if (currentUser) {
return "User is authenticated";
} else {
return "User is unauthenticated";
}
This single if statement has only two branches. If we wanted to test it, we surely need to exercise both and verify that the correct string is returned. I don’t think anyone would have difficulty here, but what if the condition is more complicated?
function canAccess(user) {
if (user.internal === false || user.featureEnabled === true) {
return true;
} else {
return false;
}
}
Here, we could have come up with the following test cases:
let user = {
internal: false,
featureEnabled: false,
};
canAccess(user); // ==> false
let user = {
internal: false,
featureEnabled: true,
};
canAccess(user); // ==> true
This would yield 100% branch coverage, but there’s a subtle bug. The internal flag was supposed to give internal users access to some feature without needing the feature to be explicitly flagged (i.e. featureEnabled: true), but the conditional checks for user.internal === false instead. This would give access to the feature to all external users, whether or not they had the flag enabled. This is why bugs exist even with 100% branch coverage. While it is useful to know if you have missed a branch during testing, knowing that you’ve tested all branches still does not guarantee that that the code works for all possible inputs.
For this reason, there are more comprehensive (and tedious) coverage strategies, such as condition coverage. With condition coverage you must test the case where each subcondition of a conditional evaluates to true and false. To do that here, we’d need to construct the following four user values (true and false for each side of the ||):
let user = {
internal: false,
featureEnabled: false,
};
let user = {
internal: false,
featureEnabled: true,
};
let user = {
internal: true,
featureEnabled: false,
};
let user = {
internal: true,
featureEnabled: true,
};
If you’re familiar with Boolean or propositional logic, these are simply the input combinations of a truth table for two boolean variables:
| internal |
featureEnabled |
| F |
F |
| F |
T |
| T |
F |
| T |
T |
This is tractable for this silly example code because there are only 2 boolean parameters and we can exhaustively test all of their combinations with only 4 test cases. Obviously bools aren’t the only type of values in programs though, and other types exacerbate the problem because they consist of more possible values. Consider this example:
enum Role {
Admin,
Read,
ReadWrite
}
function canAccess(role: Role) {
if (role === Role.ReadWrite) {
return true;
} else {
return false;
}
}
Here, a role of Admin or ReadWrite should allow access to some operation, but the code only checks for a role of ReadWrite. 100% condition and branch coverage are achieved with 2 test cases (Role.ReadWrite and Role.Read), but the function returns the wrong value for Role.Admin. This is a very common bug with enum types – even if exhaustive case matching is enforced, there’s nothing that prevents us from writing an improper mapping in the logic.
The implications of this are very bad, because data combinations grow combinatorially. If we have a User type that looks like this,
type User = {
role: Role,
internal: Boolean,
flagEnabled: Boolean
}
and we know that there are 3 possible Role values and 2 possible Boolean values, there are then 3 * 2 * 2 = 12 possible User values that we can construct. The set of possible states that a data type can be in is referred to as its state space. A state space of size 12 isn’t so bad, but these multiplications get out of hand very quickly for real-world data models. If we have a Resource type that holds the list of Users that have access to it,
type Resource = {
users: User[]
}
it has 4,096 possible states (2^12 elements in the power set of Users) in its state space. Let’s say we have a function that operates on two Resources:
function compareResources(resource1: Resource, resource2: Resource) {
...
}
The size of the domain of this function is the size of the product of the two Resource state spaces, i.e. 4,096^2 = 16,777,216. That’s around 16 million test cases to exhaustively test the input data. If we are doing integration testing where each test case can take 1 second, this would take ~194 days to execute. If these are unit tests running at 1 per millisecond, that’s still almost 5 hours of linear test time. And that’s not even considering the fact that you physically can’t even write that many tests, so you’d have to generate them somehow.
This is the ultimate dilemma: testing with exhaustive input data is the only way of knowing that a piece of logic is entirely correct, yet the size of the input data’s state space makes that prohibitively expensive in most cases. So be wary of the false security that coverage metrics provide. Bugs can still slip through if the input state space isn’t sufficiently covered.
State Introduces Path Dependence
All hours wound; the last one kills
We’ve only considered pure functions up until now. A stateful, interactive program is more complicated than a pure function. Let’s consider the following stateful React app, which I’ve chosen because it has a bug that actually occurred to me in real life.
type User = {
name: string
}
const allUsers: User[] = [
{ name: "User 1" },
{ name: "User 2" }
];
const searchResults: User[] = [
{ name: "User 2"}
];
type UserFormProps = {
users: User[],
onSearch: (users: User[]) => void
}
function UserForm({ users, onSearch }: UserFormProps) {
return <div>
<button onClick={() => onSearch(searchResults)}>
{"Search for Users"}
</button>
{users.map((user => {
return <p>{user.name}</p>
}))}
</div>;
}
function App() {
let [showingUserForm, setShowingUserForm] = useState(false);
let [users, setUsers] = useState(allUsers);
function toggleUserForm() {
setShowingUserForm(!showingUserForm);
setUsers(allUsers);
}
return (
<div className="App">
{<button onClick={() => setShowingUserForm(!showingUserForm)}>
{"Toggle Form"}
</button>}
{showingUserForm && (
<UserForm users={users} onSearch={setUsers}></UserForm>
)}
</div>
);
}
This app can show and hide a form that allows selecting a set of Users. It starts out by showing all Users but also allows you to search for specific ones. There’s a tiny (but illustrative) bug in this code. Take a minute to try and find it.
.
..
…
….
…..
……
…….
……..
………
……….
The bug is exposed with the following sequence of interactions:
- Show the form
- Search for a User
- Close the form
- Open the form again
At this point, the Users that were previously searched for are still displayed in the results list. This is what it looks like after step 4:
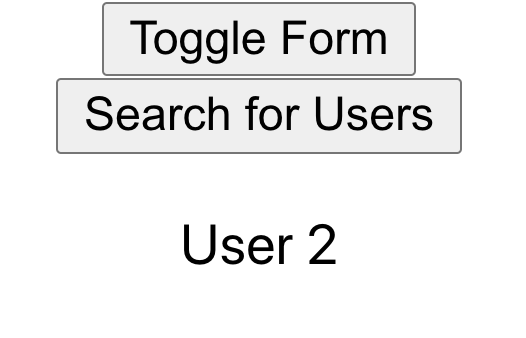
The bug isn’t tragic, and there’s plenty of simple ways to fix it, but it has a very frustrating implication: we could have toggled the form on and off 15 times, but only after searching and then toggling the form do we see this bug. Let’s understand how that’s possible.
A stateful, interactive application such as this is most naturally modeled by a state machine. Let’s look at the state diagram of this application:
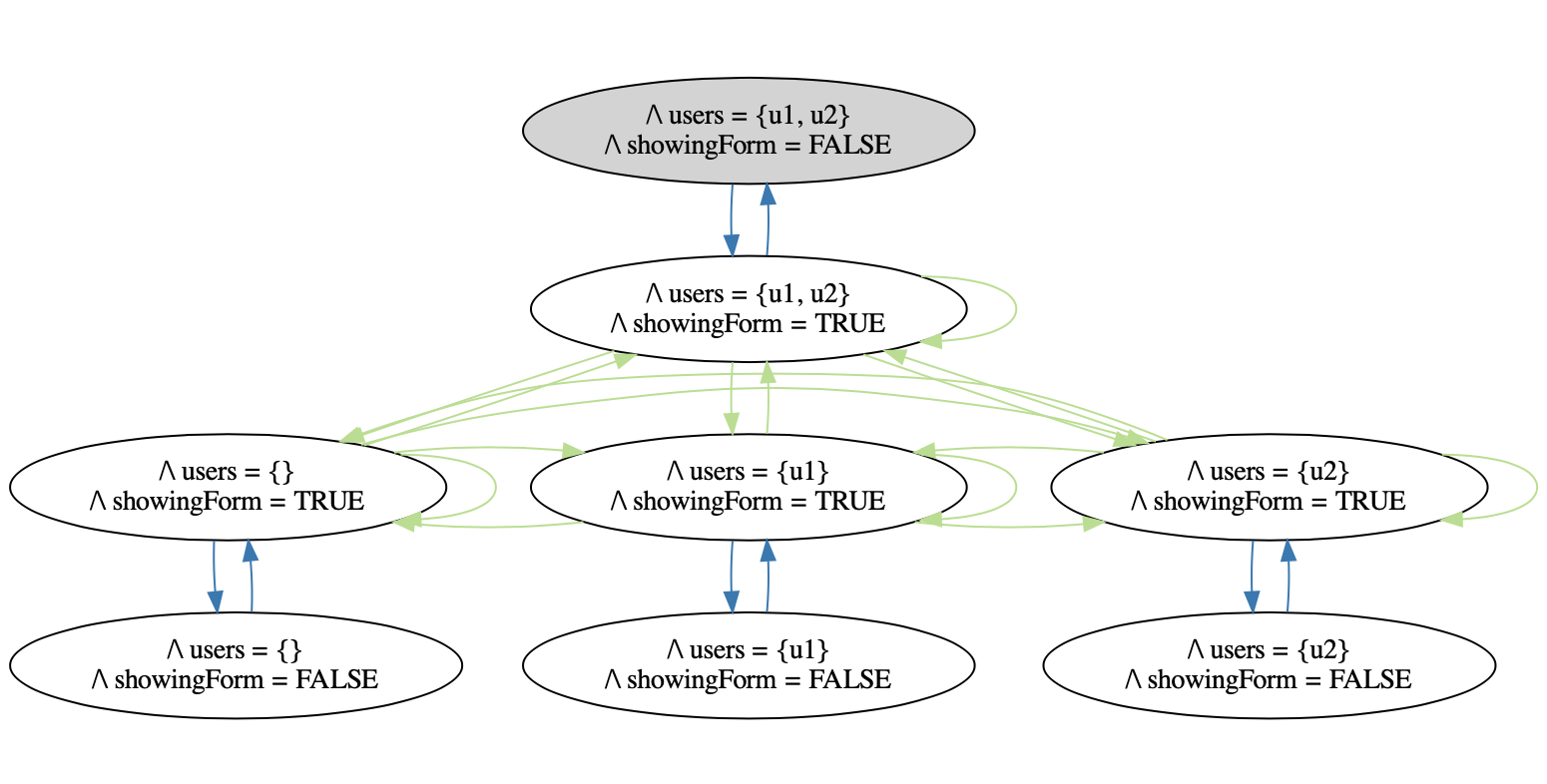
There are 2 state variables in this application: showingForm represents whether or not the form is showing, and users is the set of Users that the form is displaying for selection. showingForm can be true or false, and users can be all possible subsets of Users in the system, which for the purposes of this example we’ve limited to 2. The state space of this application then has 2 * 2^2 = 8 individual states, since we consider each individual combination of values to be a distinct state.
The edges between the states represent the actions that a user can take. ToggleForm means they click the “Toggle Form” button, and SearchForUsers means they clicked the “Search for Users” button. We can observe the above bug directly in the state diagram:
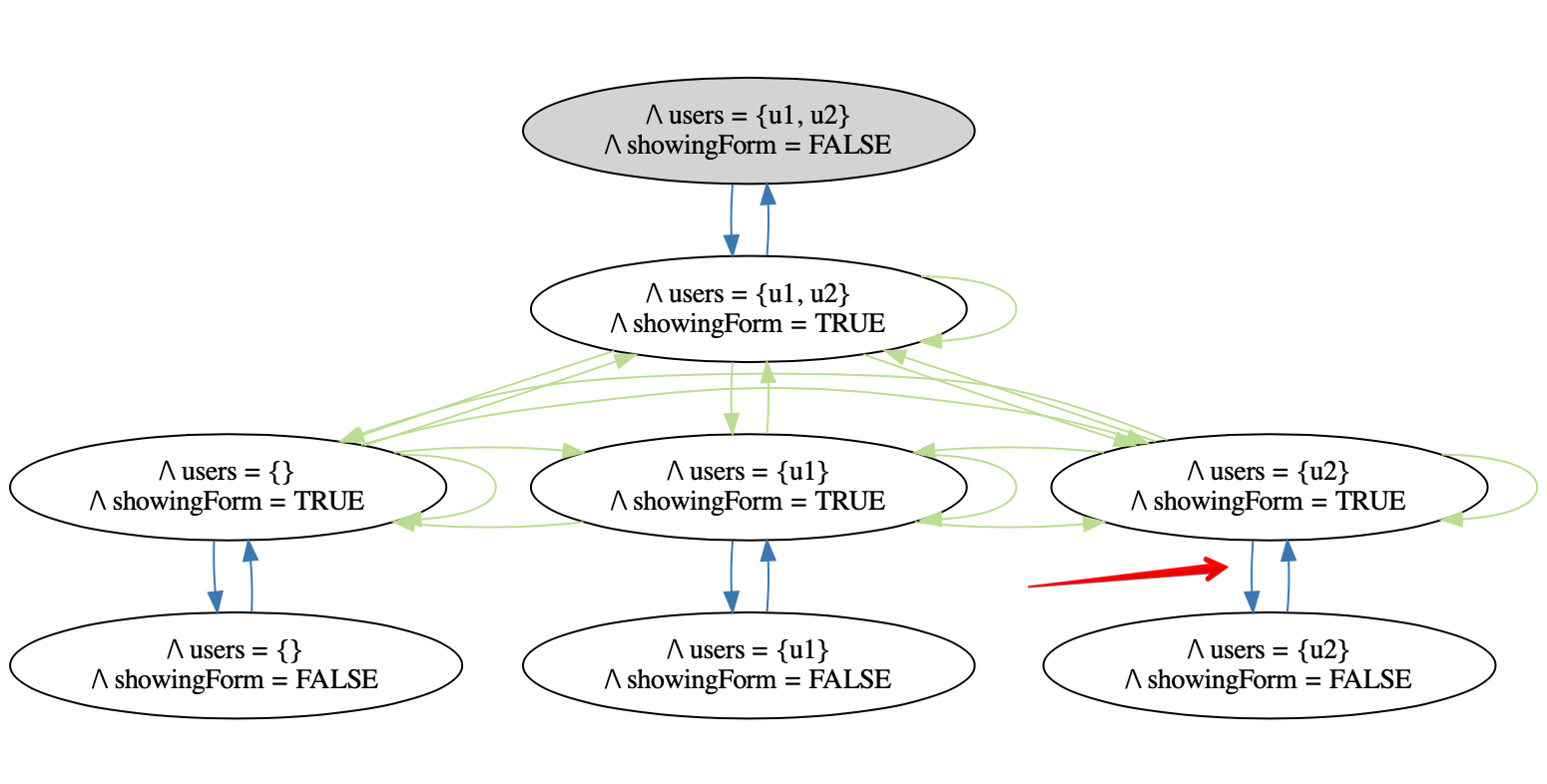
Here we see that we can hide the form after the search returns u2, and when we show the form again, u2 is still the only member of users. Note how if we only show and hide the form and never perform a search, we can never get into this state:
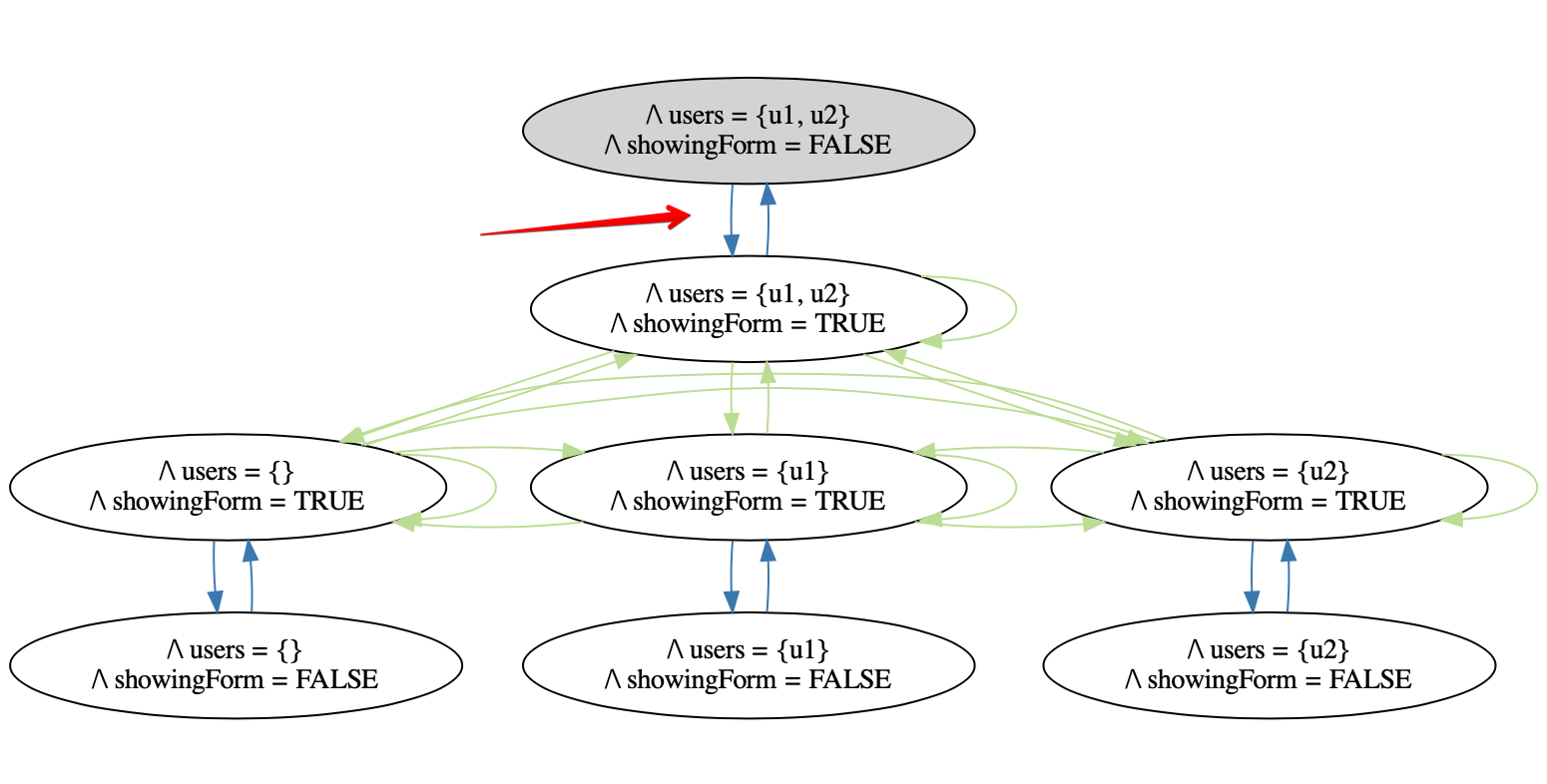
The fact that the same user action (ToggleForm) can produce a correct or buggy result depending on the sequence of actions that took place before it means that its behavior is dependent on the path that the user takes through the state machine. This is what is meant by path dependence, and it is a huge pain from a testing perspective. It means that just because you witnessed something work one time does not mean it will work the next time– we now have to consider sequences of actions when coming up with test cases. If there are n states, that means that there are n^k k-length paths through the state graph. In this extremely simplified application, there are 8 states. Checking for 4-length sequences would require 4,096 test cases, and checking for 8-length sequences would require 16,777,216.
Checking for all k-length sequences doesn’t even guarantee that we discover all unique paths in the graph– whichever k we test for, the bug could only happen at the k+1th step. The introduction of state brings the notion of time into the program. To perform a sequence of actions, you have to be able to perform an action after a previous one. These previous actions leave behind an insidious artifact: state. Programmers intuitively know that state is inherently complex, but this is shows where that intuition comes from. Like clockmakers, we know know how powerful the effect of time is, and clockmakers have a saying that’s relevant here:
Omnes vulnerant, ultima necat
It means: All hours wound; the last one kills.
It seems that our collective intuition is correct, and we should try and avoid state and time in programs whenever we can. Path dependence adds a huge burden to testing.
State Explosion
Faster, higher, stronger
A state graph consists of one node per state in the state space of the state variables, along with directed edges between them. If there are n states in the state space, then there can be n^2 edges in the corresponding state graph. We looked at the state diagram of this application with 2 users, now here is the state diagram when there are 4 total Users (remember, more Users means more possible subsets, and every unique combination of data is considered a different state):

The number of nodes went from 8 to 32 states, which means there are 1,024 possible edges now. There are constraints on when you can perform certain actions, so there are a fewer number of edges in this particular graph, though we can see that there are still quite a lot. Trust me, you don’t want to see the graph for 10 Users.
This phenonmenon is known as state explosion. When we add more state variables, or increase the range of the existing variables, the state space multiplies in size. This adds quadratically more edges and thus more paths to the state graph of the stateful parts of the program, which increases the probability that there is a specific path that we’re not considering when testing.
The number of individual states and transitions in a modern interactive application is finite and countable, but it’s almost beyond human comprehension at a granular level. Djikstra called software a “radical novelty” for this reason– how are we expected to verify something of this intimidating magnitude?
What Does This Mean for Testing?
Frankly, it proves that testing software is inherently difficult. Critics of testing software as a practice are quick to point out that each test case provides no guarantee that other test cases will work. This means that, generally, we’re testing an infinitesimal subset of a potentialy huge state space, and any member of the untested part can lead to a bug. This is a situation where the magnitude of the problem is simply not on our side, to the point where it can be disheartening.
Yet, we have thousands of test cases running on CI multiple times a day, every day, for years at a time. An enormous amount of computational resources are spent running test suites all around the world, but these tests are like holes in swiss cheese – the majority of the state space gets left uncovered. That’s not even considering the effect that test code has on the ability to actually modify our applications. If we’re not dilligent with how we structure our test code, it can make the codebase feel like a cross between a minefield and a tar pit. The predominant testing strategy of today is to create thousands of isolated test cases that test one specific scenario at a time, often referred to as example-based testing. While there are proven benefits to testing via individual examples, and after doing it for many years myself, I’ve opened my mind to other approaches.
The anti-climax here is that I don’t have the silver bullet for this problem, and it doesn’t look like anyone else does either. Among others, we have the formal methods camp who thinks we can prove our way to software quality, and we have the ship-it camp who thinks it’s an intractable problem so we should just reactively fix bugs as they get reported. We have techniques such as generative testing, input space partitioning, equivalence partitioning, boundary analysis, etc. I’m honestly not sure which way is “correct”, but I do believe that a) it is a very large problem (again, just consider how much compute time every day is dedicated to running test suites across all companies), and b) conventional wisdom is mostly ineffective for solving it. I have more stock in the formal methods side, but I think there are things that go way too far such as dependent typing and interactive theorem proving- it can’t take 6 months to ship an average feature, and developer ergonomics are extremely important. I’ll leave the solution discussion there and tackle that in subsequent posts.
However we approach it, I’m sure that the state space magnitude problem is at the root of what we need to solve to achieve the goal of high software quality.